
Many science fiction writers predicted the creation of virtual voice assistants. And with the development of machine learning and artificial intelligence, speech recognition systems have become a reliable assistant in everyday life.
In modern voice recognition applications, there are serious engineering and natural language processing( NLP) algorithms. Despite the relative complexity of development, the market for virtual assistants continues to grow. So, today we will talk about all aspects of how to make a speech recognition program.

What is a Speech Recognition System?
A voice recognition system is software that "listens" to speech, transforms it into text understandable by a computer, and then manipulates the received data. Almost all modern mobile operating systems have their own voice and speech recognition software to help the user and provide information.

Siri is one of the most advanced speech recognition software. It can give advice by users’ request and execute commands under their guidance. In general, speech recognition programming greatly simplifies our lives. It allows us to receive important information when we are in a hurry and don’t have time to search the Internet or not be distracted from the road while driving. It is a significant time-saver since the average person speaks 125-150 words per minute while typing only 40 words. In 2019, the U.S. voice recognition technology market was $11 billion, and it is expected to grow by 17% by 2025.
History of Speech Recognition Technology
It may seem surprising, but the first experiment to create a machine that recognizes speech dates back to 1,000 AD. A scientist and church leader named Pope Sylvester II developed an instrument that could answer "yes" or "no" questions. Sylvester II used Arab scientific advances to create his devices. Although it was not speech recognition technology, it still used the foundation on which modern software is built: using natural language as input to trigger an action.
Now the speech recognition systems are widely used in many devices and are also part of smart home systems. Even though the first attempts to create similar tools were adopted centuries ago, these technologies have been actively developing over the past 70 years.
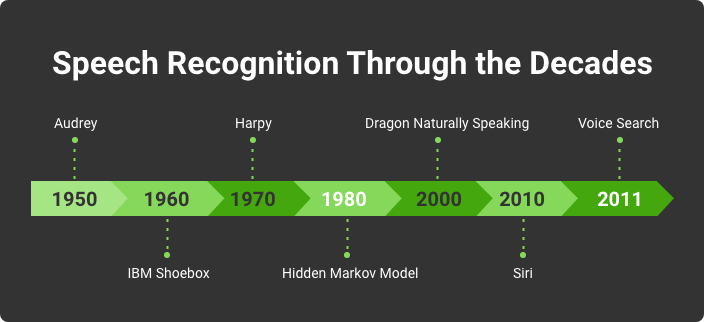
Speech Recognition Through the Decades
In 1952, three scientists from Bell Labs developed a device called "Audrey,” which recognized prime numbers from 1 to 9 spoken with one voice.
10 years later, IBM presented a speech recognition system that could "understand" 16 words, including numbers. The system could recognize simple sentences and print the answer out on paper.
A breakthrough happened in the 1970s. The Defense Advanced Research Projects Agency (DARPA) invested in a program called Speech Understanding Research for 5 years. As a result, they created a device called Harpy that "understood" 1011 words. For those times, it was a real win.
In 1970-1980, the Hidden Markov Model was first used for speech recognition. The essence of the model is an emulation of the operation of a random process with unknown parameters. The task of the model is to guess unknown parameters based on the observables. Later, this statistical model was widely used to simulate problems with sequential information and formed the basis of many speech recognition software.
In 1997, the Nuance company launched Dragon Naturally Speaking, which recognized human speech and transformed it into text. The application had hints. It analyzed the words of the dictator, and in a pop-up window, showed unspoken words that fit the structure and meaning of the sentence.
The voice recognition revolution was made by Siri, which was released in 2010 by Siri Inc. After 4 months, Apple bought the software, which eventually became an integral part of devices controlled by iOS. Siri responds to requests, provides recommendations, and interacts with each user individually, analyzing all their requests and behavior.
In 2011, Google released a Voice Search application that aimed at helping users to surf the Internet using voice commands. The application was compatible with Google Chrome. It allowed users to make a voice request, then looked for answers online.
How Speech Recognition Works
Surrounded by smart gadgets, it seems to us that speech recognition is commonplace. But in reality, it is still a complicated process, even in the information technology age. Just as a small child listens to parents and learns to understand them, speech recognition algorithms have also developed. We taught machines to "understand" what we want from them and send us the needed information. But this process does not stand still, and we continue to teach computers to recognize more and better. Despite that it's possible to write a whole book on this topic, we will try to briefly and easily explain how such programs work.
Simple Word Pattern Matching
This is the easiest way to convert sound to text, which is later processed by the machine. It involves recognizing whole words based on their sound signature. Such systems are often used in answering machines, such as when you call a service center, and the system asks you to pronounce your name or number. The first thing the program does is convert the signal into a form that the machine can understand. Basically, a spectrogram is used for this. This graph has a Y-axis showing frequency, an X-axis showing time and intensity represented in color.
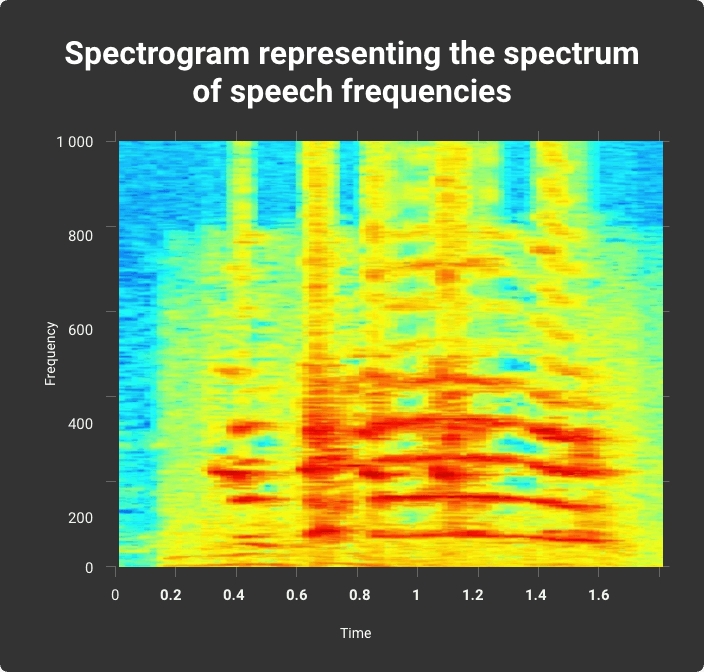
Spectrogram representing the spectrum of speech frequencies
A spectrogram represents every word in the “memory” of the software. It compares the spectrogram of the word spoken with the spectrograms from its vocabulary to determine what was said. In general, this method does an excellent job of recognizing simple words.
Pattern And Feature Analysis
The disadvantage of the previous model is that it has a limited vocabulary. Theoretically, it could be significantly expanded because people’s vocabularies are very different, and many also have dialects. In turn, it complicates the analysis process for selecting patterns. So, learning blocks that recognize sounds have been invented. It helps the system to understand whole sentences. This is precisely the basis of feature analysis.
Statistical Analysis And Modeling
Some more advanced voice recognition systems are based on the language model. They can listen and understand the words that people say because they have mathematical algorithms for analyzing languages. This method is also built on the rule that a different set of words can follow certain words, while other words are rarely used in the same sentence. For example, it is more likely that the word "open" will be followed by the word "door.” The statistical analysis and modeling method has been actively used over the past 10 years and has reached its development limit. And this means that for better voice recognition programming, more advanced technologies are required.
Artificial Neural Networks (ANNS)
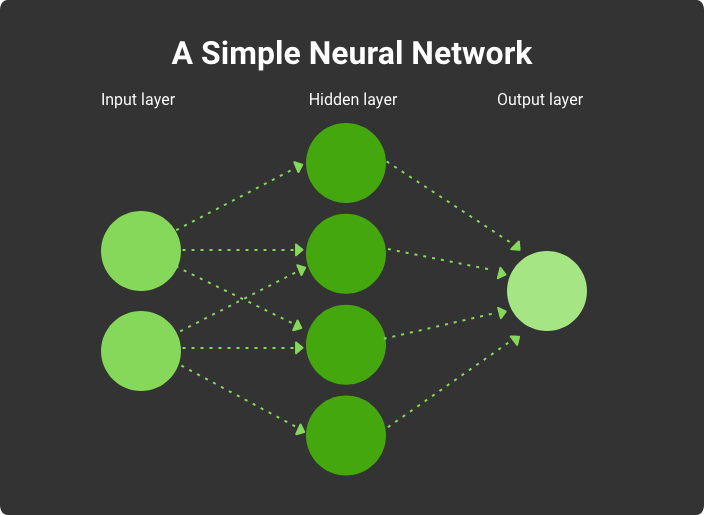
This is how a simple neural network works
Modern systems for speech, text, and photo recognition use neural networks. This is a mathematical model, and its hardware and software implementation allows the computer to work like a human brain. Instead of storing specific patterns, it uses vast networks of neurons that change connections with each other as new information flows through them. But there are also some difficulties here. In order for the neural system to be able to work and develop independently, it will have to be trained using extensive databases.
At KeyUA, we have been creating quality software with machine learning and artificial neural networks technologies for over 5 years.
Contact UsPopular Voice Assistants
Let's now see what products have succeeded in human speech recognition. And we will start with the one we have already talked about, which made a breakthrough in speech recognition.
Apple’s Siri
Siri was the first voice assistant to be successfully hit the market and integrated into Apple devices. Siri is a development of the International Center for Artificial Intelligence (SRI), an offshoot of a DARPA-funded project described as arguably the largest artificial intelligence project to date. Siri's speech recognition engine was developed by Nuance Communication, but neither Nuance nor Apple admitted this for a long time. Apple’s voice assistant uses sophisticated machine learning techniques to efficiently process queries in real-time, convolutional neural networks, and long-term vs. short-term memory.
It is now used as the primary user interface in the Apple CarPlay infotainment system for cars and integrated with all Apple devices. The user can say "Siri, take me to the airport" or "Siri, I need a car to the train station," and the software will open the travel booking applications installed on the phone. Being the first is never easy, and Siri has received a flurry of criticism from many customers. Nevertheless, its voice recognition libraries continue to be updated, resulting in the program more accurately "understanding" the user. Apple’s voice assistant is available in more than 40 countries in over 20 languages and some dialects.
Amazon Alexa
This virtual assistant first appeared on Amazon Echo and Amazon Echo Dot smart speakers in 2014. The assistant supports voice communication, playing music, podcasts and audiobooks, making to-do lists, setting alarms, providing up-to-date information about weather, traffic, sports, news, etc., and controlling devices in a smart home. Users can empower Alexa by installing "skills" developed by third-party vendors.
Unlike Apple, Amazon does not impose restrictions on its software’s ability to perform only a certain range of tasks, allowing Alexa to be one of the top speech recognition applications. In addition, it adapts to the user's voice, which helps Alexa understand better over time, even if they speak a dialect.
Microsoft’s Cortana
Cortana was released in 2014 as part of the Windows Phone 8.1 software and was a 26th century AI character from the Halo video game series. After 3 years, Microsoft announced that Cortana's speech recognition rate had reached an accuracy of 95%.
Cortana is designed to anticipate user needs. If desired, she can be given access to personal data such as e-mail, address book, history of searches on the web, etc. - all this data she will use to predict the user’s needs. Also, the virtual assistant is not devoid of a sense of humor: she can maintain a conversation, sing, and tell anecdotes. She will remind you in advance of a scheduled meeting, a friend's birthday, and other important events. The interface has flexible privacy settings that allow users to determine what kind of information to provide to the virtual assistant. Cortana has an age limit - users whose Microsoft accounts are below 13 years old will not be able to use the virtual assistant's services.
Google Assistant
It is a cloud-based personal assistant service that was released in 2016. Despite the fact that the software was launched on the market 2 years after the release of Alexa, it quickly won the love of users, and a year later, it was considered a significant competitor for the Amazon speech recognition system. Google Assistant not only answers correctly but also provides additional context and links to the original website for information. It is available in over 90 countries and 30 languages. Google claims that over 500 million people use their Virtual Assistant every month.
Nuance’s Dragon Assistant and Dragon Naturally Speaking
DragonDictate (prototype of Dragon NaturallySpeaking) was first released for DOS and used Hidden Markov Models, a probabilistic method for recognizing temporary patterns. At the time, the hardware was not powerful enough to solve the word segmentation problem, and DragonDictate was unable to detect word boundaries during continuous speech input. Users were forced to speak one word at a time, clearly separated by a small pause after each word.
Nowadays, Dragon Naturally Speaking is the basis for speech recognition among many popular products (for example, Siri). It uses a minimal interface and has three main functionalities: voice recognition during dictation with speech-to-written text, voice command recognition, and text-to-speech, reading out the text content of a document.
How to Create Voice Recognition Software
There are 9 basic steps to deliver a speech recognition project. This process takes time, and in general, you will need at least 12 weeks to prepare the product.
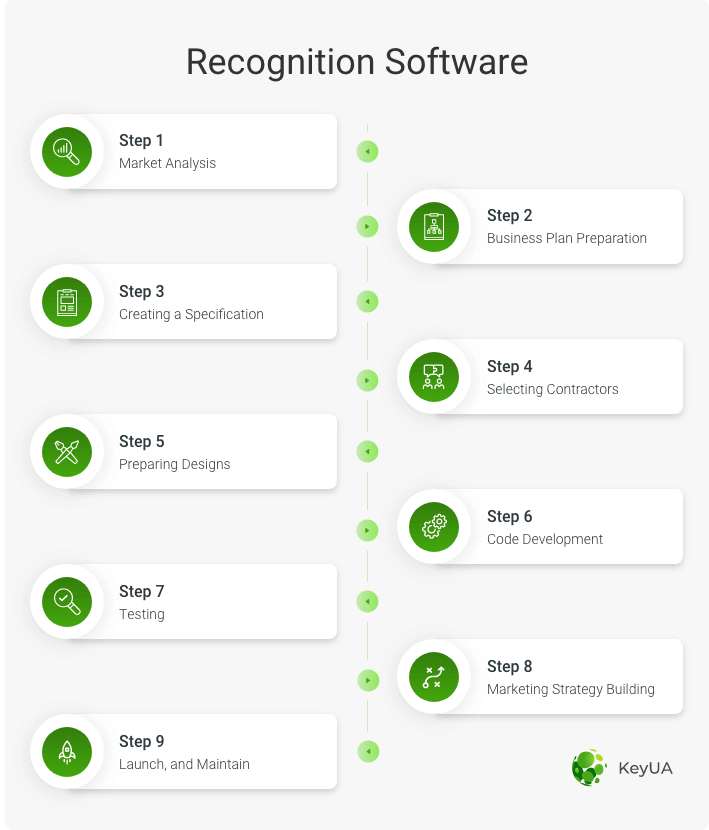
How to Make a Speech Recognition Software
#1 Market Analysis
Voice recognition systems are popular throughout the world. They are used in a variety of applications, from defense to children's toys. In 2015, the Hello Barbie doll was released, which had artificial intelligence and was designed to recognize children's speech. It supports more than 8000 lines of dialogues. This widespread use of technology suggests that market analysis is essential no matter the size of your project. If you plan to make a voice recognition program for commercial needs, you should carefully study the niche, competitors in your field, preferences, and behaviors of potential customers. Software becomes successful when it solves certain users' issues. Analysis of potential customers and their characteristics allows you to determine which functionality will be most in demand.
If you create software for your own needs (for example, only your employees will use it), you will still have to do a market analysis to understand what existing tools are better to use while saving time and development costs.
#2 Business Plan Preparation
The business plan analyzes all aspects of the project and ways of product distribution. This document is essential, even if you think you are building a simple application. First, a business plan allows you to think about solutions in advance for all sorts of problems a company may face. Secondly, by having this document, you can effectively control the consumption of resources for software development. Finally, this is an excellent opportunity to attract investors if you need additional funding.
#3 Creating a Specification
Your next step is documenting how the finished product should work. In the specification, you have to describe how the system will perceive sounds (through a microphone, audio files, etc.), how users will interact with the application, and its additional features. All this will later become the basis for the development of the code.
#4 Selecting Contractors
This is an essential step since the quality of your product will depend on the experience and knowledge of the developers. You can hire freelancers or an IT outsourcing company. Usually, the services of freelancers are cheaper, but this also has its drawbacks. If your project requires more than one developer, you will have to search and hire each specialist yourself. This is a time-consuming process. And if you have never done it before, then you risk hiring non-professional personnel. IT companies provide dedicated teams. This means that your project will be worked on by as many specialists as you need, including developers, designers, testers, and marketers.
When choosing a contractor, also pay attention to what technologies they use. At the moment, Python, which is an open-source programming language, is especially popular when creating a voice recognition system. In Python, developers can use various speech identification services through the API.
#5 Preparing Designs
Take care of preparing the page layouts for your application. If the designer is someone from the contractor's company, it will be a significant advantage. Together with the developers, they can think over in detail a first-class and convenient interface for your product.
#6 Code Development
The next step is the longest and includes building the project architecture and generating the source code. Development can take three months or more, depending on the scale of the required product. This process is based on transforming the specification into workable software, configuring the server, and installing the database. Building a speech recognition system implies writing algorithms for neural systems and machine learning. These are complex technologies that only professional programmers can deliver in a quality manner.
#7 Testing
Before a product reaches the end-user, it must be thoroughly tested. This is the responsibility of the quality assurance team. Unfortunately, many companies skip this step, trying to save money, ultimately leading to even higher costs or project failure. Testing is about checking the product’s actual functionality and comparing it with the specification requirements and business logic. This step allows you to identify all the flaws in the system and voice recognition methods before your customers try the product. Testing is a guarantee that the market will receive high-quality software.
#8 Marketing Creation
In parallel with testing your product, you should start developing strategies for promoting your product to the market. If you are creating software for the internal needs of your company, this step can be skipped. In all other situations, you need a strong marketing campaign to launch a product successfully.
#9 Launch and Maintain
Once development and testing are complete, it's time to market your product and launch promotion campaigns. If you have created a mobile application for Android and/or iOS, it should be published in the appropriate Stores. But app development doesn't end there. A truly successful product involves maintaining the functionality and periodically updating the tools. Since voice recognition technologies are constantly being updated, your product will also require changes to meet market needs and IT trends.
Conclusion
Now speech recognition systems are widely used in many devices and are also part of smart home systems. Although the first attempts to create similar tools were adopted centuries ago, these technologies have been actively developing over the past 70 years.
Voice typing is an efficient form of computing that makes our daily tasks easier. Modern, powerful systems are built based on several programming languages: Python, Java, C ++, Objective-C. Their libraries and engines are continually being updated, making speech recognition systems more accurate. Many studies predict that the role of virtual assistants in our lives will become more significant. So building voice recognition software is a great business idea.
Have a great idea, and want to make custom voice recognition software? Great, let's put your concept into practice at the highest level!
Contact Us




 Unit 1505 124 City Road, London, United Kingdom, EC1V 2NX
Unit 1505 124 City Road, London, United Kingdom, EC1V 2NX

Comments
Leave a comment